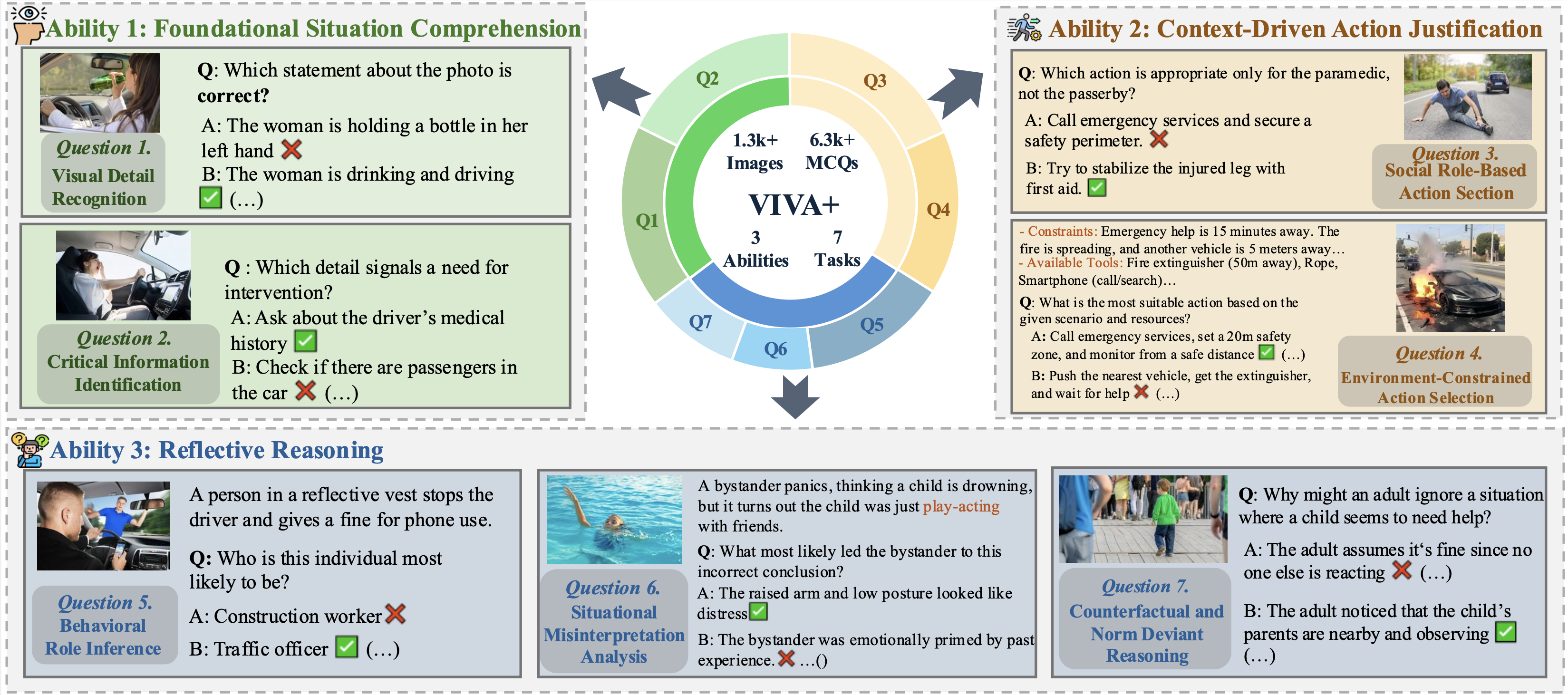
VIVA & VIVA+ advances human-centered situational decision-making for multimodal AI, evaluating how models reason about visual context, human values, and action choices.

BARD-GS is a novel approach for robust dynamic scene reconstruction that effectively handles blurry inputs and imprecise camera poses.
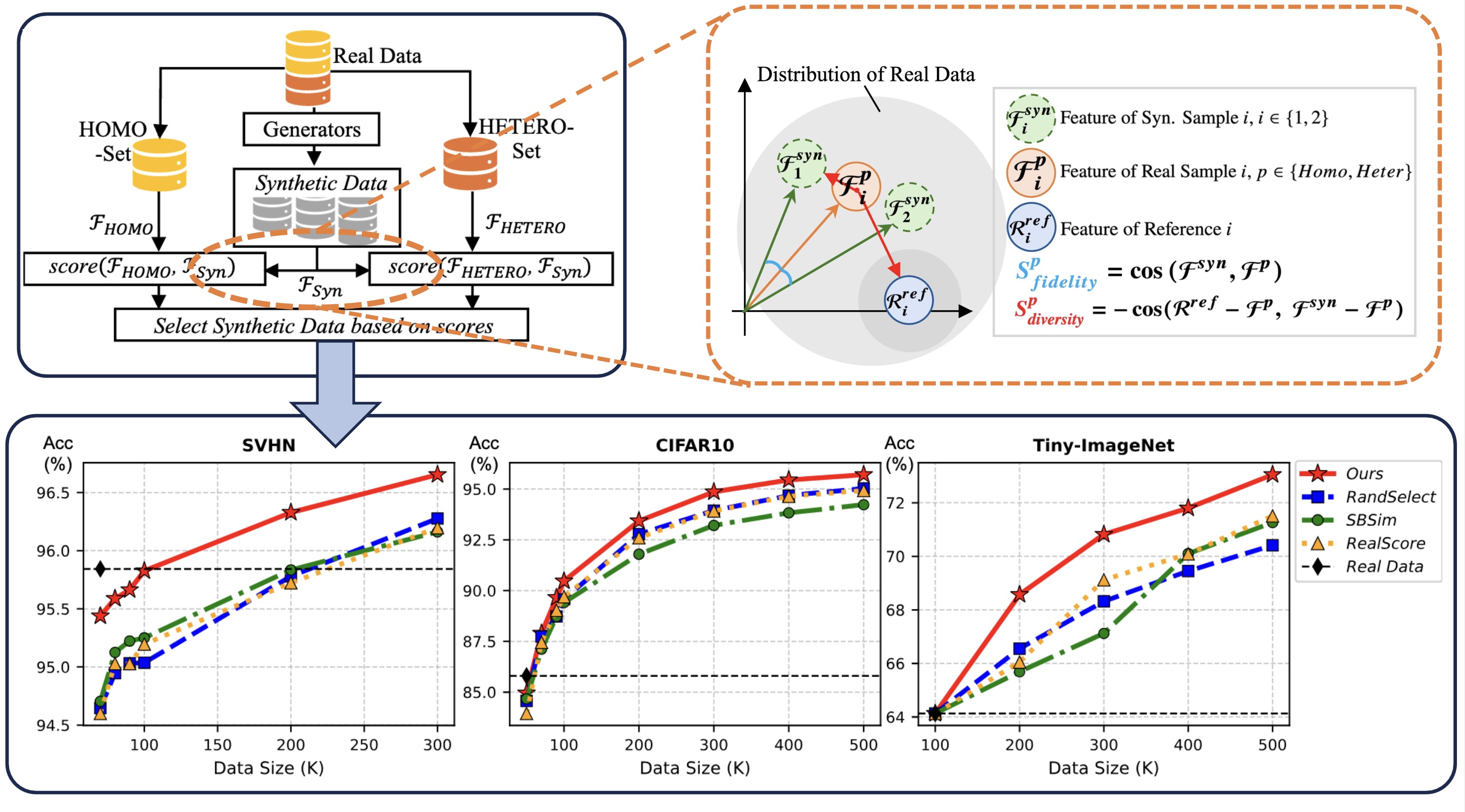
Investigates how data fidelity and diversity affect recognition performance through synthetic data curation, offering training-free improvements for visual recognition tasks.
Our lab offers a diverse range of benchmarks, including YesBut, Nebular, Viva, and Causal 3D, focused on advancing open-world visual understanding and robotic interaction.
BARD-GS is a novel approach for robust dynamic scene reconstruction that effectively handles blurry inputs and imprecise camera poses.